-
Product

Cluster Upgrades
Detect schema changes, duplicates & nulls effortlessly.

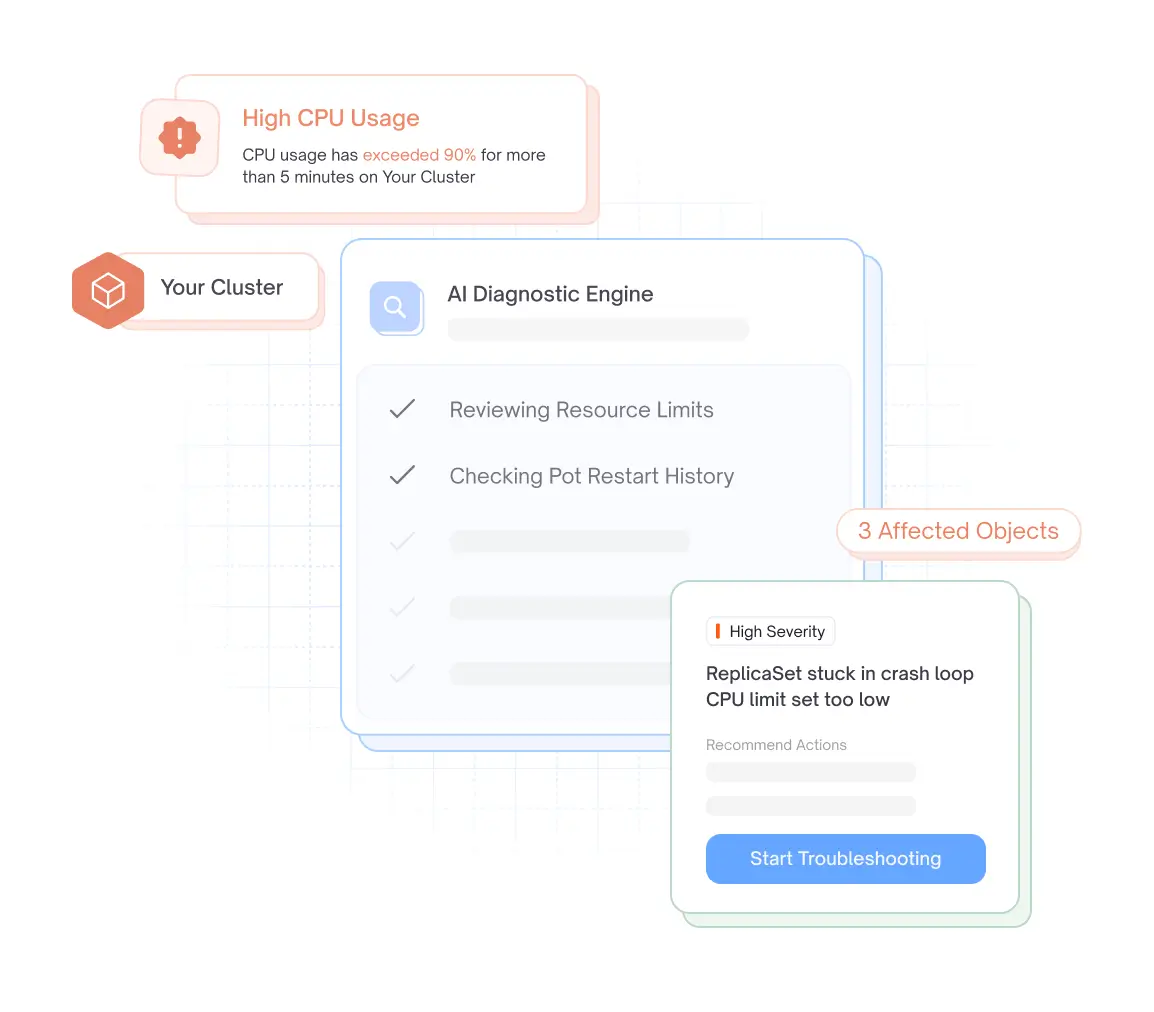
Troubleshooting
Simplify governance and build trust in your data.

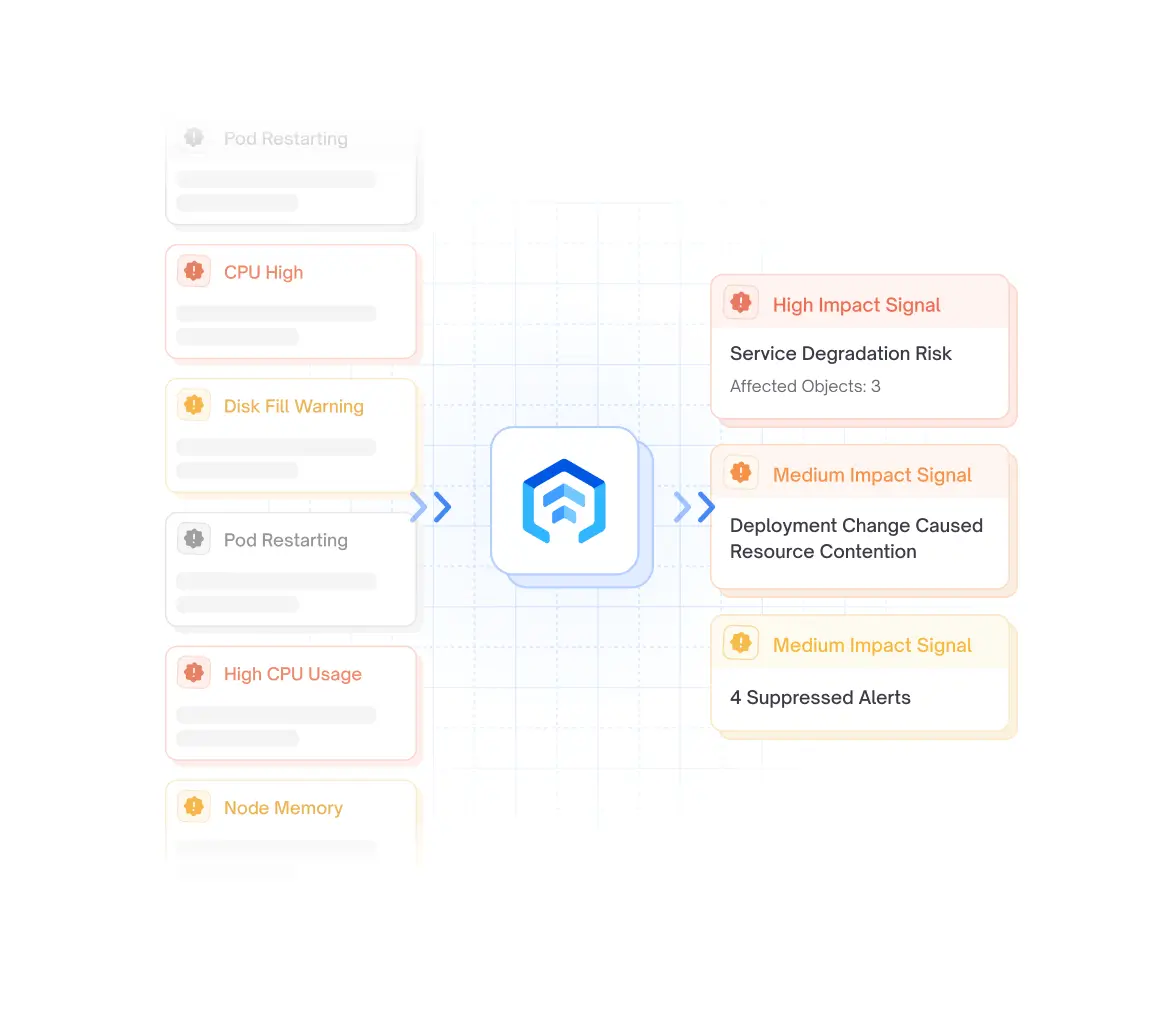
Alert Sorting
Discover, understand, and organize assets thoroughly.

Drift Monitor
Unveil bottlenecks for reliable pipelines that meet SLAs.

Kube Assistant (AI Agent)
Simplify governance and build trust in your data.
GitOps Remediation
Discover, understand, and organize assets thoroughly.
Cluster Visualization
Unveil bottlenecks for reliable pipelines that meet SLAs.
Fleet Management
Discover, understand, and organize assets thoroughly.
Security
Detect schema changes, duplicates & nulls effortlessly.

Kubegrade Product Walkthrough
Unified platform for Kubernetes Day-2 operations.
- Solution
- Resources